Whenever Scraping is talked about, XPATH, CSS, or RegEx are usually mentioned, but there is another way to extract content from a site, and that is by intercepting the calls made by the site to its services, like Google.
Let’s use Google site as an example on how we can achieve that. Just for practical reason obviously.
For those who are not familiar, Scraping is a practice that involves extracting information from one or several sites. Although the legality of this practice is a bit gray, companies of all types do it, with Google being the king of it.
Googlebot is the most active bot on the internet.
How can scraping be done without needing the DOM?
Identify the endpoint calls
Let’s take the last script I made as an example, which extracts data from autocomplete.
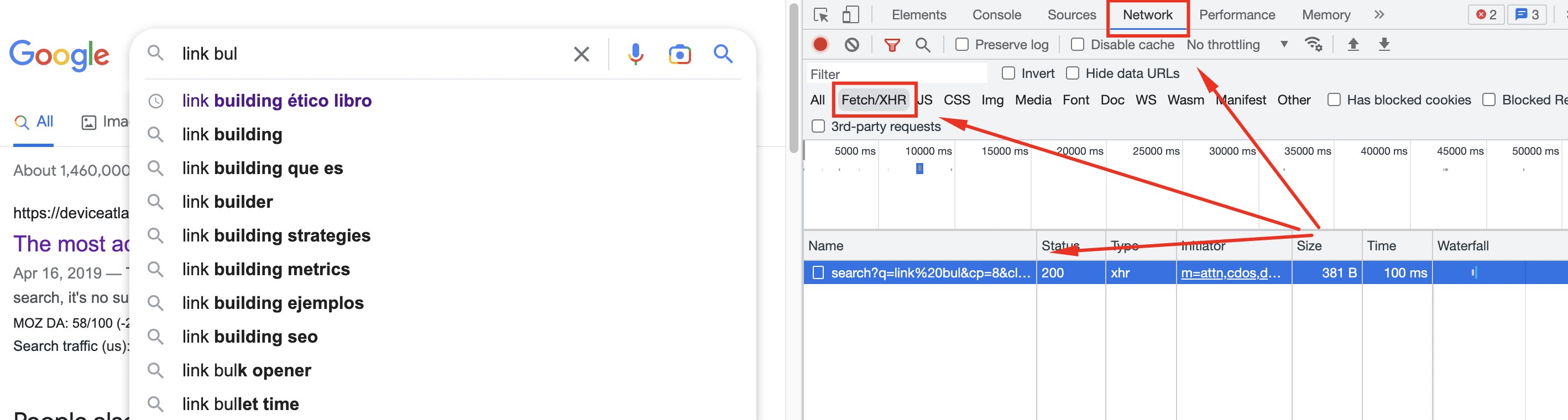
The first thing to do is to see what calls the site makes when certain actions happen.
For example, in Google, when we type something in the search bar and autocomplete appears, a call is made to request that data. You can see it in Dev Tools > Network > Fetch/XHR.
Emulate the same payload
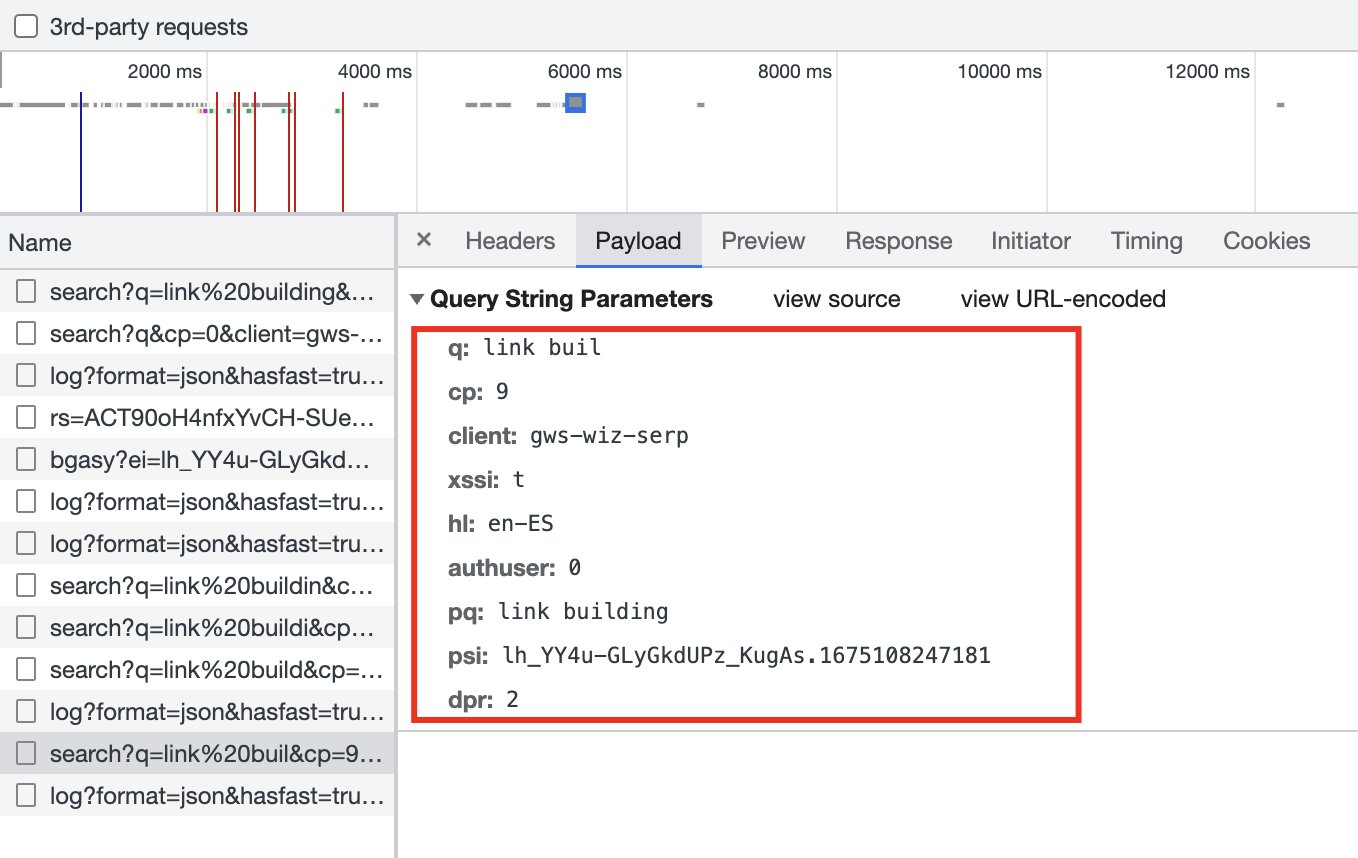
Once we have identified which request the site is making, we click on it to see what payload it is sending.
That is the body of the request and what it needs to receive in order to return the autocomplete data.
Let’s continue.
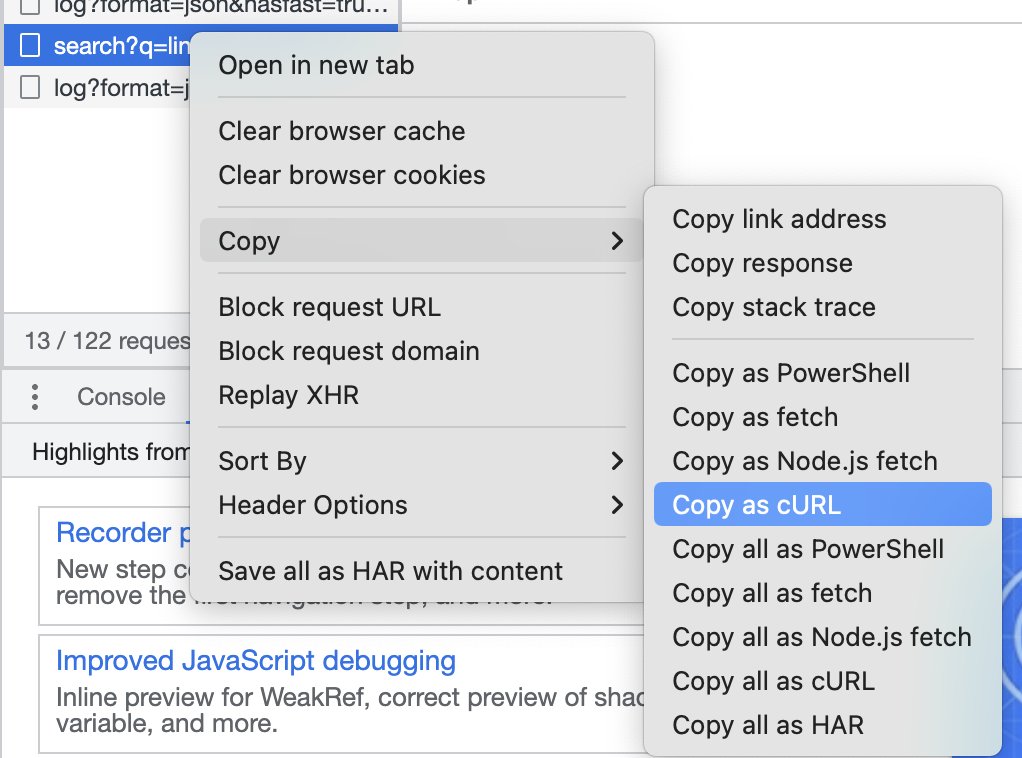
To be able to quickly emulate that call, we can right-click on the URL and select copy > copy as cURL.
This way, we have the entire call copied so we can paste it into our terminal.
Fecth in local with cURL
We open the terminal and paste the call to see which elements we will need and which ones we won’t (in order to format it in the language of our choice, whether it be Python, NodeJS, or another).
Viewing the terminal like this is a bit like seeing the matrix, I know.
Now we will change that.
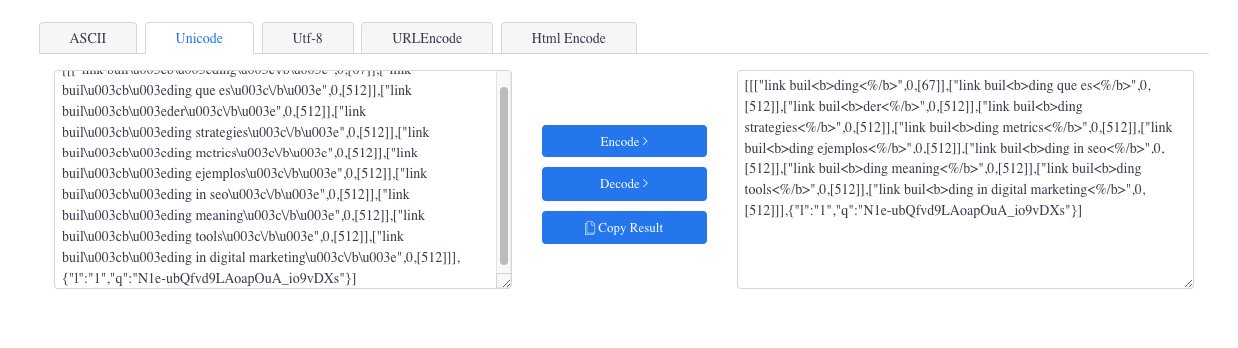
We execute the request to see what the response is: a list of terms in Unicode format.
Decode unicode format
To make it more readable, we can use a converter.
Now it’s a little clearer.
We have to capture the data, but let’s make it a little more scalable.
Let’s use NodeJS.
Scaling the scraping with NodeJS
We transform the cURL request to Axios (a library for making requests).
We will pass it the query for which we want the information and the language to modify the hl attribute (I’m not sure if using a VPN when executing it would be optimal for getting results by country).
And we add to the script that it iterates over each letter of the alphabet to extract the autocomplete of the query + letter and save the result in a .txt file.